
Lesson 55: Platform Engineering - Building Internal Developer Platforms
What We’re Building Today
Today we architect and deploy a production-grade Internal Developer Platform (IDP) on Kubernetes that abstracts infrastructure complexity while maintaining operational control:
Self-Service Developer Portal: React-based interface enabling developers to provision environments, deploy applications, and monitor services without Kubernetes expertise
Multi-Tenant Platform Backend: FastAPI service orchestrating Kubernetes resources across namespaces with RBAC isolation and quota enforcement
GitOps Integration Layer: Automated reconciliation engine syncing Git repositories to cluster state using ArgoCD and custom operators
Developer Experience APIs: Abstraction layer transforming simple developer intents (”deploy my service”) into complex Kubernetes manifests with security policies, networking, and observability pre-configured
Why Platform Engineering Matters at Scale
The infrastructure complexity tax becomes exponential as engineering organizations scale. At companies processing billions of requests daily, developer productivity directly impacts business velocity. Consider Spotify’s infrastructure evolution: their engineering teams were spending 40% of sprint capacity managing Kubernetes YAML, debugging networking policies, and configuring observability—tasks orthogonal to product development.
Internal Developer Platforms solve the “infrastructure cognitive load” problem by creating curated golden paths. Netflix’s platform team reduced deployment time from 4 hours to 8 minutes by abstracting 147 Kubernetes resources into a single API call. Uber’s platform handles 4,000 deployments daily across 100+ microservices with zero manual kubectl commands from product engineers.
The operational insight: platforms shift complexity left into reusable automation while maintaining the flexibility needed for genuine innovation. This lesson builds an IDP that balances abstraction with transparency—developers get simplicity for common paths while retaining escape hatches for custom requirements.
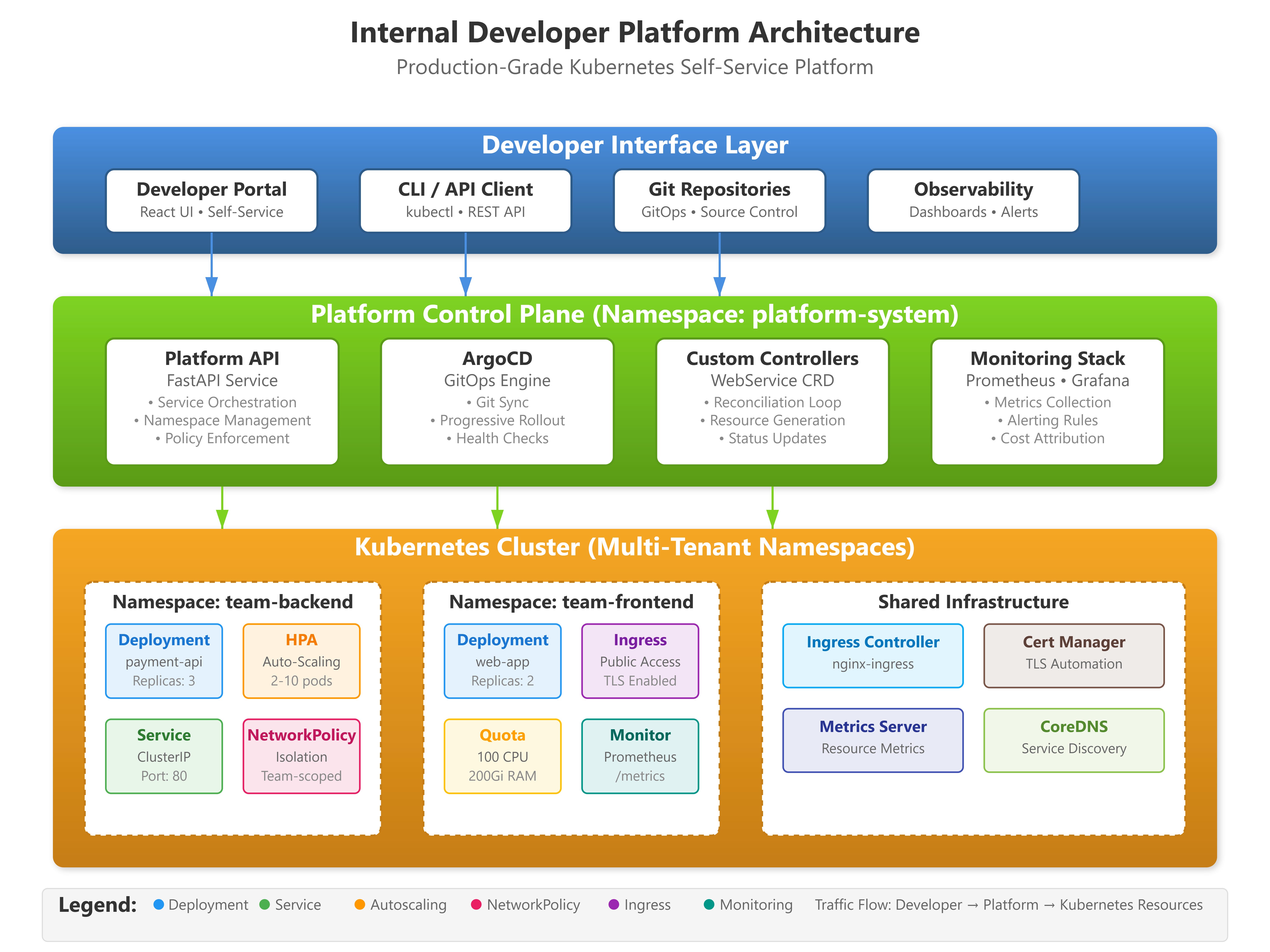
IDP Architecture: Core Kubernetes Patterns
Preparing for a distributed systems interview?
→Download the free Interview Pack
→ Subscribe now to access source code repository - 200 + coding lessons
1. Multi-Tenancy Through Namespace Federation
Production IDPs implement strict tenant isolation using Kubernetes namespaces as isolation boundaries. The critical pattern: programmatic namespace provisioning with embedded policies rather than manual configuration.
The platform controller generates namespaces with three embedded resources: ResourceQuota limiting compute allocation per team, LimitRange setting container-level defaults and boundaries, and NetworkPolicy enforcing zero-trust networking between tenants. Each namespace receives labels for team attribution, enabling cost allocation and policy scoping.
The architectural trade-off: namespace-per-team provides strong isolation but increases cluster resource overhead. Airbnb runs 2,000+ namespaces per cluster, requiring tuned etcd configurations and optimized controller reconciliation loops. The key insight: namespace provisioning must be idempotent and include cleanup policies to prevent quota exhaustion from abandoned resources.
2. Declarative Service Abstractions with Custom Resources
IDPs extend Kubernetes with domain-specific APIs through Custom Resource Definitions (CRDs). This pattern replaces imperative deployment commands with declarative service definitions that abstract infrastructure complexity.
A WebService CRD encapsulates deployment intent: runtime language, scaling parameters, resource tier, networking configuration, and observability requirements. The platform controller watches these custom resources and reconciles them into 15-20 underlying Kubernetes objects: Deployment with security contexts, HorizontalPodAutoscaler, Service, Ingress with TLS, NetworkPolicy scoped to dependencies, PodDisruptionBudget for availability, and ServiceMonitor for Prometheus.
Key insight: The abstraction level determines platform adoption. Too high-level and edge cases require workarounds; too low-level and developers bypass the platform. Stripe’s platform provides three tiers: “Managed” (zero configuration for 90% of cases), “Configured” (common overrides for specialized needs), and “Advanced” (full Kubernetes access for 5% of edge cases). This progressive disclosure pattern maximizes adoption while preventing abstraction leakage.
3. Progressive Delivery Through GitOps Operators
Modern IDPs implement GitOps as the deployment substrate, treating Git as the source of truth for desired cluster state. The pattern uses ArgoCD or Flux with custom health checks and progressive rollout policies that platform APIs control programmatically.
The platform controller generates ArgoCD Application resources for each WebService, configuring automated sync policies, rollback triggers, and health assessment windows. Progressive delivery strategies layer on top: canary deployments start at 10% traffic, pause for automated analysis of error rates and latency percentiles, then progress to 50% and finally 100% based on success criteria.
The operational challenge: GitOps introduces eventual consistency where cluster state lags repository changes by 30-180 seconds. High-velocity teams compensate with optimistic UI updates showing intended state while WebSocket connections stream real reconciliation status. The critical pattern: separate the intent (Git commit) from reality (cluster state) in all user interfaces.
4. Golden Path Templates with Policy Enforcement
IDPs encode organizational best practices as default configurations enforced at API admission time. The pattern: layered policy enforcement from cluster-wide defaults through team conventions to application-specific overrides.
Platform APIs inject security contexts (runAsNonRoot, seccompProfile, readOnlyRootFilesystem), resource boundaries based on tier selection, and observability sidecars when tracing is enabled. Open Policy Agent (OPA) Gatekeeper provides admission control with 50-100 constraint templates covering security (no privileged containers), compliance (required labels for cost attribution), and operational (mandatory resource limits) requirements.
The architectural decision: fail-closed on policy violations during API request time, not post-deployment validation. This prevents non-compliant resources from reaching the cluster while providing immediate feedback to developers. Companies running large platforms use OPA dry-run mode for 2 weeks when introducing new constraints, measuring violation rates before enforcement.
5. Cost Visibility and Optimization Automation
Production IDPs surface resource costs to development teams, enabling informed capacity decisions. The pattern integrates Kubecost or custom metrics exporters with team-level attribution through namespace labels and pod annotations.
Cost dashboards show per-team burn rates with trends, idle resource identification (CPU utilization <10% sustained), and rightsizing recommendations based on actual usage percentiles. Automated optimization applies recommendations after 14 days of stable metrics with automatic rollback on latency degradation—LinkedIn’s platform saves 35% on compute costs through this approach.
Critical insight: cost visibility changes behavior only when connected to team budgets with accountability. Spotify’s platform links namespace quotas to quarterly capacity allocations, forcing teams to optimize before requesting increases. The key metric: cost per deployment as a platform efficiency indicator.
Implementation Walkthrough
GitHub Link :
The IDP deploys across four Kubernetes namespaces with distinct responsibilities:
Platform Control Plane (platform-system namespace) runs the FastAPI service handling developer requests. It authenticates via OIDC, validates requests against team quotas, generates Kubernetes manifests from WebService specs, and applies them using service account impersonation scoped to team namespaces. The critical pattern: use controller-runtime to watch CRD changes rather than HTTP webhooks, enabling continuous reconciliation and automatic recovery from partial failures.
Developer Portal UI (platform-frontend namespace) provides the self-service interface. React components call platform APIs over GraphQL, displaying real-time service status via WebSocket subscriptions. Key consideration: the UI reflects actual cluster state with <5s latency, not cached assumptions, requiring efficient Kubernetes watch streams.
GitOps Reconciliation (argocd namespace) manages application lifecycle. Platform APIs create ArgoCD Application resources programmatically; ArgoCD handles Git sync, health assessment, and rollback automation. Trade-off analysis: ArgoCD requires 1.5GB baseline memory versus 200MB for Flux, but provides superior visualization—choose based on team GitOps maturity and available cluster capacity.
Observability Stack (monitoring namespace) consolidates metrics, logs, and traces. Prometheus federation scrapes team-level instances to avoid cardinality explosion (10M+ time series at 500+ applications). Grafana dashboards auto-generate from service annotations. Jaeger spans flow through Istio sidecars when observability.tracing is enabled in WebService specs.
Working Demo Link :
Production Considerations
Multi-Cluster Federation becomes necessary at 10+ clusters. Implement cluster selectors in WebService specs allowing teams to target geographic regions or compliance zones. Use cluster API aggregation for unified control plane access—Airbnb’s platform API fronts 50+ regional clusters through a single endpoint.
Disaster Recovery requires continuous backup of platform state (CRD instances, ArgoCD applications, team quotas). Velero schedules capture namespace resources every 6 hours. Recovery RTO: <30 minutes for control plane, <2 hours for full tenant restoration. Test recovery quarterly with actual cluster rebuilds.
Capacity Planning accounts for platform overhead consuming 15-20% of cluster resources. Budget 4 CPU / 8GB RAM per 100 applications for platform components. Node autoscaling requires 30-60s buffer for pod scheduling during traffic spikes—underprovisioning causes deployment failures during scale events.
Security Boundaries enforce strict privilege separation. Platform APIs use impersonation with per-team service accounts, never cluster-admin. Audit all API calls for compliance. Network policies default-deny between team namespaces. Container images scan with Trivy in CI/CD, blocking high/critical vulnerabilities.
Breaking Changes follow Kubernetes versioning (v1alpha1 → v1beta1 → v1). Maintain backwards compatibility for 2 minor versions minimum with deprecation warnings. Automated migration scripts handle CRD version upgrades during cluster updates.
Scale Connection: FAANG Platform Patterns
Netflix Titus: Manages 3 million container launches daily across 500,000 CPU cores. Their platform API abstracts 14 deployment patterns into 3 developer templates, reducing configuration errors by 90%. Key insight: they version platform APIs independently from Kubernetes versions, allowing cluster upgrades without developer impact.
Airbnb Kubernetes Platform: Supports 2,000 microservices with 30,000 deployments monthly. Platform-enforced resource quotas prevented $4M annual cloud waste through automated rightsizing. Critical pattern: cost dashboards embedded in deployment workflows, showing projected monthly spend before approval.
Spotify Backstage: Open-sourced IDP handles 14,000 engineers across 300+ clusters. Platform metrics show 75% reduction in time-to-first-deployment (4 weeks → 1 week). The architectural decision: Backstage provides service catalog and developer portal while delegating Kubernetes orchestration to underlying platforms—separation of concerns at scale.
The universal pattern: successful platforms measure developer productivity metrics (deployment frequency, lead time, MTTR) rather than infrastructure metrics (uptime, resource utilization). Platform engineering shifts from “keeping systems running” to “accelerating product velocity through infrastructure automation.”
Key Architectural Insight
The fundamental IDP design tension: standardization versus flexibility. Over-standardized platforms force teams into workarounds and shadow IT solutions—platform escape velocity where avoiding the platform is easier than using it. Under-standardized platforms fail to capture operational expertise, leaving teams reinventing solutions and repeating mistakes.
Resolution strategy: implement progressive disclosure of complexity. The platform provides three interfaces:
Simplified tier (target 90% adoption): Zero Kubernetes knowledge required. Developers specify language runtime, scaling bounds, and public/private networking. Platform generates all infrastructure with security and observability built-in.
Customization tier (5-10% of use cases): Override specific behaviors through structured annotations. Examples: custom health check paths, specialized autoscaling metrics, additional environment variables. Requires basic Kubernetes understanding but prevents common errors.
Escape hatch tier (<5% of cases): Full Kubernetes manifest control for genuine edge cases. Platform validates against security policies but allows necessary flexibility. Used for specialized workloads like ML training, data pipelines, or legacy applications with unique requirements.
Success metric: percentage of deployments using simplified tier trending upward indicates successful golden path design. Increasing escape hatch usage over time signals missing abstractions requiring platform evolution. The key insight: platforms are never “done”—they evolve with organizational needs through continuous developer feedback and usage analytics.
Hi, thanks for your content! Unfortunately It seems this link: https://github.com/sysdr/k8-course-p/tree/main/lesson55 does not exist!