
Lesson 53 : High-Performance Networking in Kubernetes: SR-IOV, DPDK, and the Path to Wire-Speed Throughput
What We’re Building Today
By the end of this lesson you will have deployed and understood:
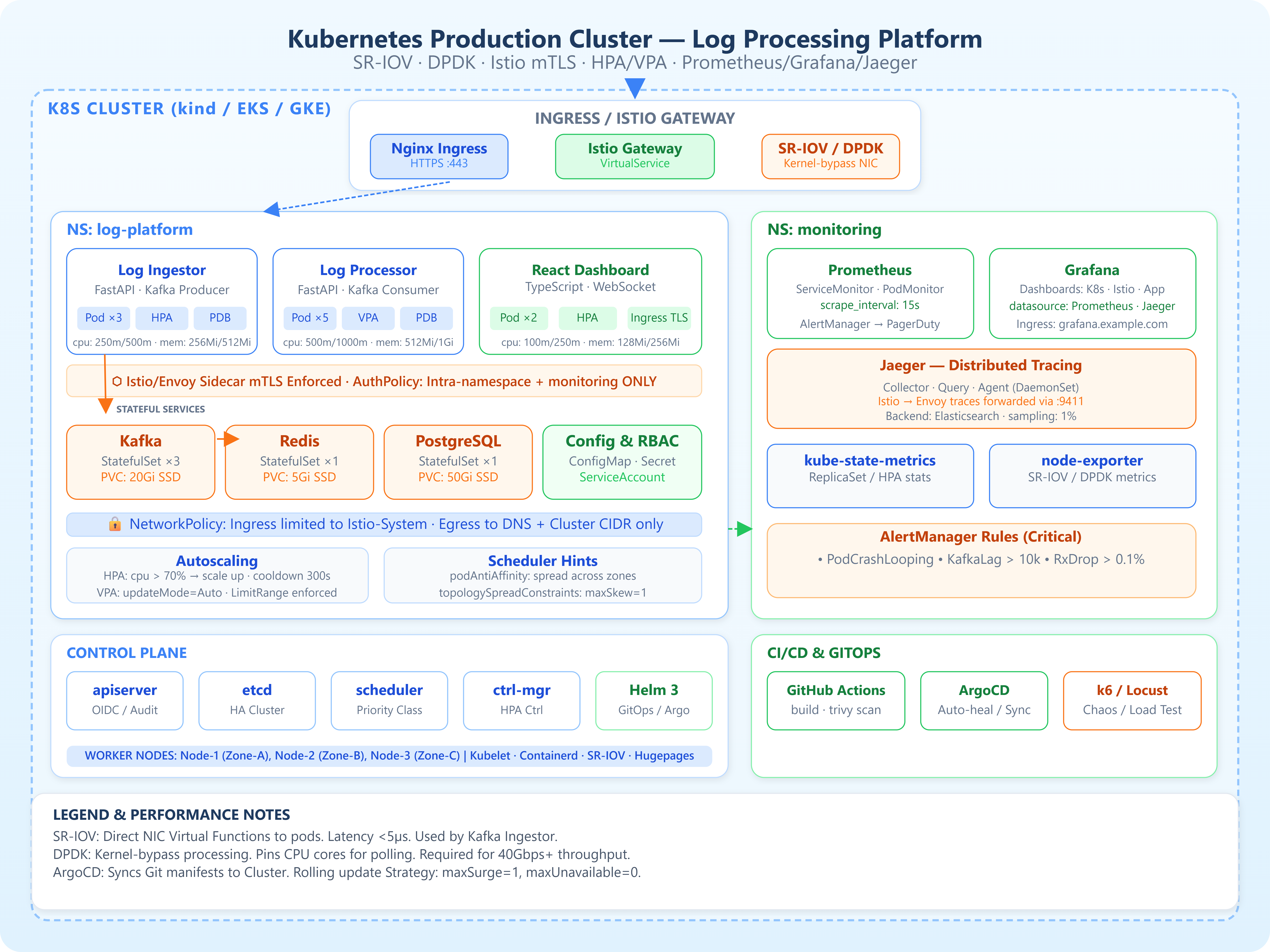
A production-grade log-processing microservices platform on Kubernetes, with FastAPI ingestors, Kafka-backed processors, and a React analytics dashboard — all communicating through an Istio service mesh with enforced mTLS
SR-IOV Virtual Function assignment to high-throughput pods, eliminating the kube-proxy iptables bottleneck and achieving kernel-bypass networking at the pod level
DPDK-enabled OVS datapath configured via Multus CNI as a secondary interface, with hugepage allocation, CPU pinning, and PMD metrics scraped into Prometheus
A complete observability stack (Prometheus, Grafana, Jaeger) wired to emit DPDK PMD counters, SR-IOV VF statistics, and Istio Envoy telemetry — all correlated via distributed trace IDs
Why This Matters
Most Kubernetes networking guides stop at
kube-proxy,CNI plugin, and “pods can talk to services.” That’s not where production systems operate.At Kafka-scale ingestion — think hundreds of thousands of log events per second from a fleet of services — the Linux kernel networking stack becomes the ceiling. The kernel’s
softirqbudget, the overhead of iptables rule evaluation on every packet, the context-switch cost of moving data between NIC ring buffers and userspace: these accumulate into measurable P99 latency degradation and CPU cycles stolen from your actual application logic.Netflix’s edge nodes processing 40Gbps+ of media delivery traffic, Spotify’s event pipeline ingesting billions of client-side events per day, Cloudflare’s Kubernetes-native edge router — none of them are running standard kernel networking on their critical path pods. They’re using the same primitives this lesson teaches: SR-IOV for hardware-level isolation and direct VF-to-pod assignment, DPDK for userspace packet processing where kernel context switches cannot be tolerated.
The architectural decision isn’t “use fancy networking because it sounds cool.” It’s understanding the inflection point — the request rate, the latency SLO, the packet size distribution — at which standard Linux networking becomes the bottleneck, and having the tooling to bypass it deliberately.
Kubernetes Architecture Deep Dive
Preparing for a distributed systems interview?
→Download the free Interview Pack
→ Subscribe now to access source code repository - 200 + coding lessons
