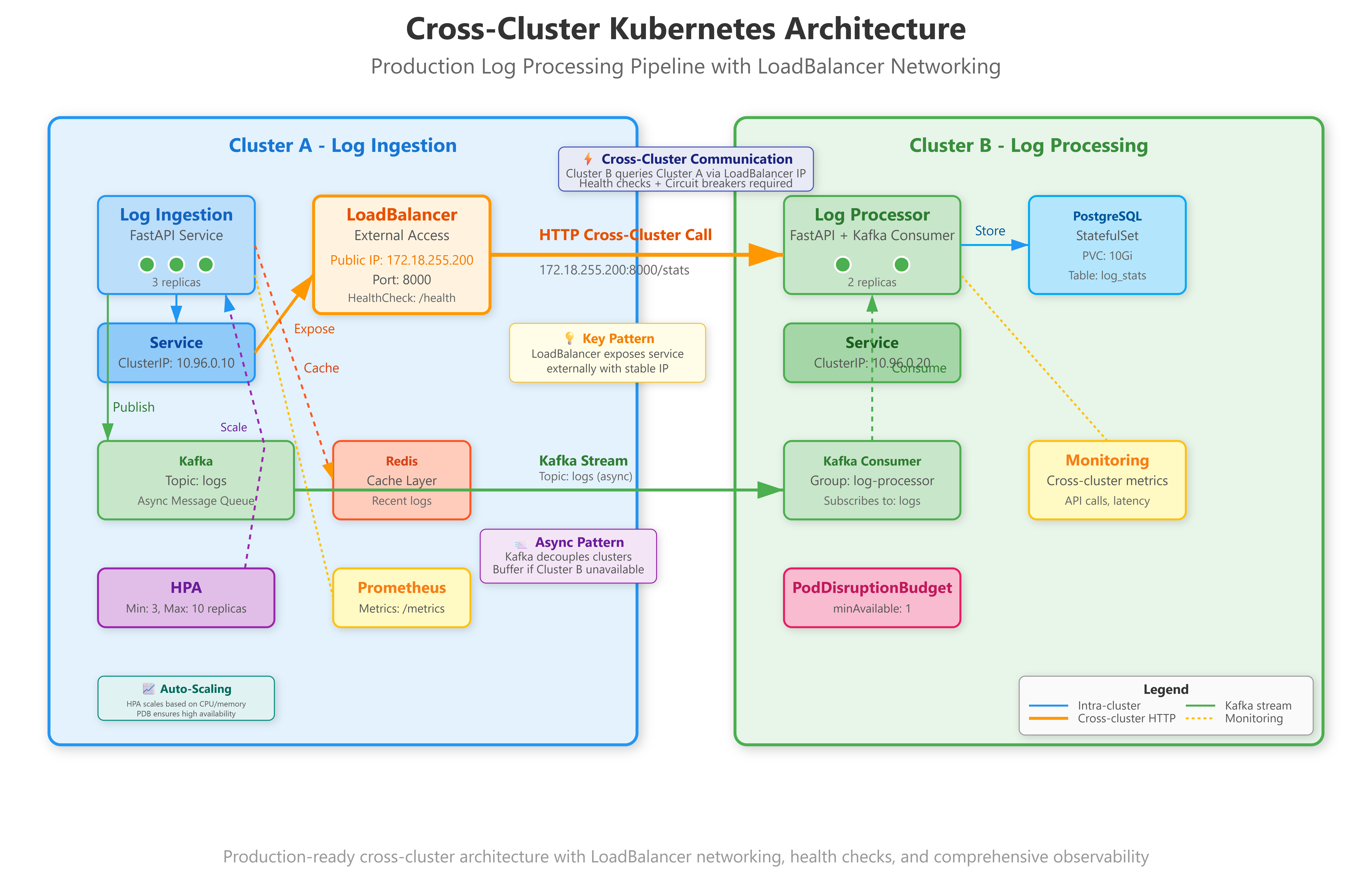
Lesson 47: Cross-Cluster Networking - Production-Grade Multi-Cluster Communication
What We’re Building Today
Today’s implementation delivers a production-ready cross-cluster networking system demonstrating:
Dual-cluster log aggregation pipeline with service exposure across cluster boundaries via LoadBalancer
DNS-based service discovery enabling seamless cross-cluster communication without hardcoded IPs
Health-aware traffic routing with automatic failover between cluster endpoints
Comprehensive observability stack monitoring cross-cluster latency, throughput, and failure patterns
Why This Matters: The Multi-Cluster Reality
Modern cloud-native platforms don’t operate as single monolithic clusters. Organizations run multiple Kubernetes clusters for regulatory compliance (data sovereignty), blast radius containment (a compromise in one cluster doesn’t cascade), geographic distribution (edge computing and latency optimization), and operational isolation (dev/staging/prod separation).
The challenge isn’t running multiple clusters—it’s enabling services across these clusters to communicate with production-grade reliability. Netflix operates dozens of regional clusters; a recommendation service in us-east-1 must query user preferences in eu-west-1 with sub-100ms latency. Spotify’s playlist generation spans clusters across three continents, requiring seamless cross-cluster RPC. These aren’t academic exercises—they’re operational realities where naive solutions create cascading failures.
Cross-cluster networking introduces distributed system challenges: network partitions between clusters, variable latency across cloud provider backbones, DNS resolution complexity, and certificate trust boundaries. The LoadBalancer pattern we implement today is foundational—it’s the primitive that higher-level service meshes (Istio multi-primary, Linkerd multi-cluster) and orchestrators (Karmada, Cluster API) build upon.