Lesson 46: Multi-Cluster Architectures - Orchestrating Kubernetes at Planetary Scale
What We’re Building Today
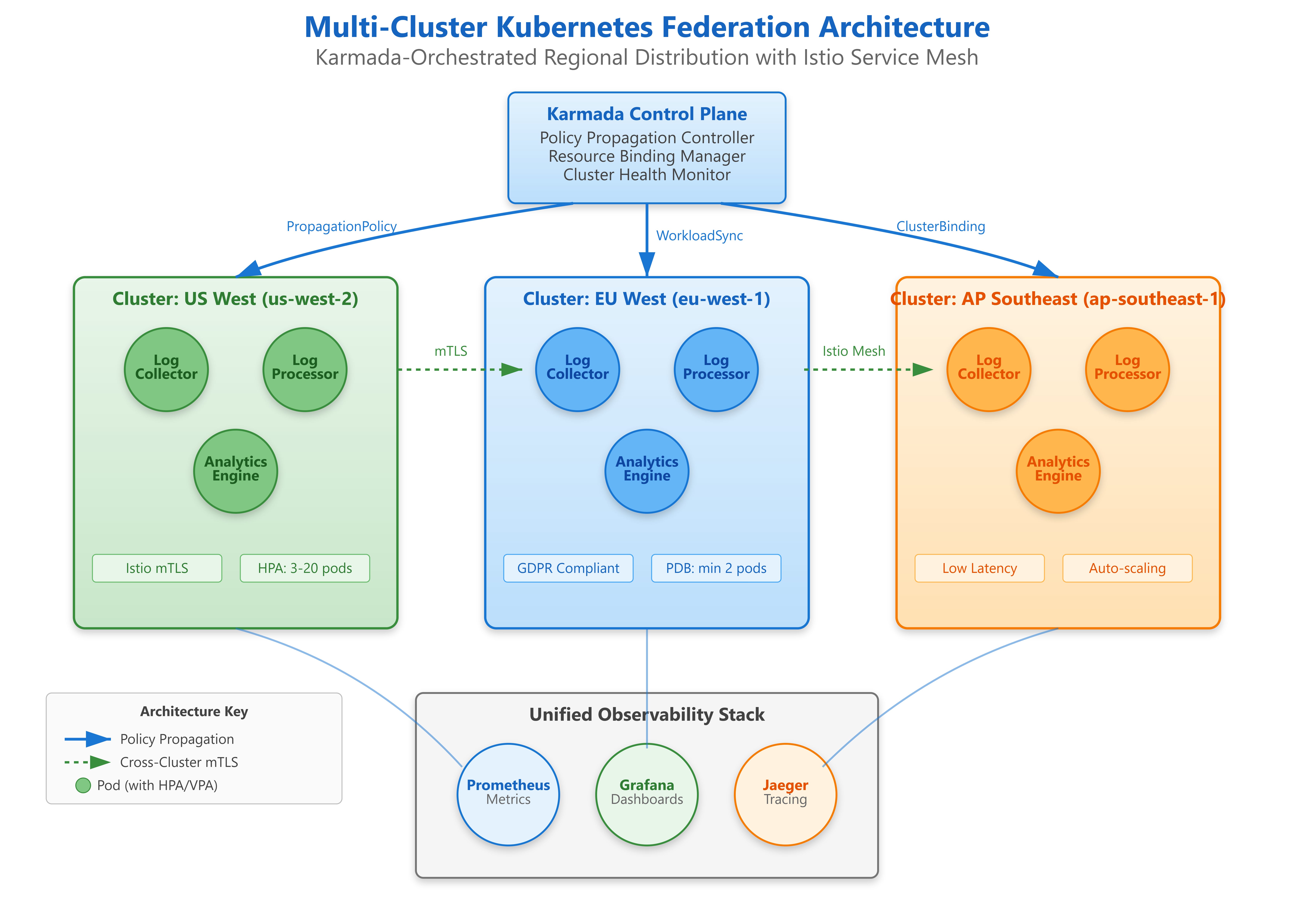
Production multi-cluster federation system with Karmada orchestrating workloads across 3 geographic regions
Cross-cluster service discovery enabling seamless communication between distributed microservices
Unified control plane managing cluster lifecycle, policy propagation, and failover automation
Complete observability stack providing global visibility across federated Kubernetes infrastructure
Why This Matters: The Multi-Cluster Imperative
Single-cluster Kubernetes hits fundamental limits around 5,000 nodes and 150,000 pods—limits that Netflix, Uber, and Spotify exceeded years ago. But the technical ceiling isn’t the primary driver for multi-cluster adoption. The real reasons are operational: blast radius containment, regulatory compliance, and the physics of latency.
When a cluster-level failure occurs—and it will, whether from etcd corruption, control plane cascading failures, or catastrophic network partitioning—you want the blast radius limited to one region, not your entire global infrastructure. Multi-cluster architecture transforms cluster failures from existential crises into routine failover events.
Geographic distribution addresses the speed-of-light problem that single-cluster architectures cannot solve. A user in Singapore accessing services from a us-east-1 cluster experiences 180ms+ baseline latency before application logic even executes. Multi-cluster deployments with regional affinity routing reduce this to sub-20ms, directly impacting conversion rates and user retention.
Regulatory requirements increasingly mandate data residency—GDPR in Europe, data localization laws in India and China. Multi-cluster federations with policy-driven workload placement ensure compliance without sacrificing operational consistency. You define placement policies once; the federation controller handles the geographic complexity.
Multi-Cluster Architecture Patterns: Strategic Trade-offs