Lesson 29: Data Pipelines - Building Production-Grade Kafka Streaming on Kubernetes
What We’re Building Today
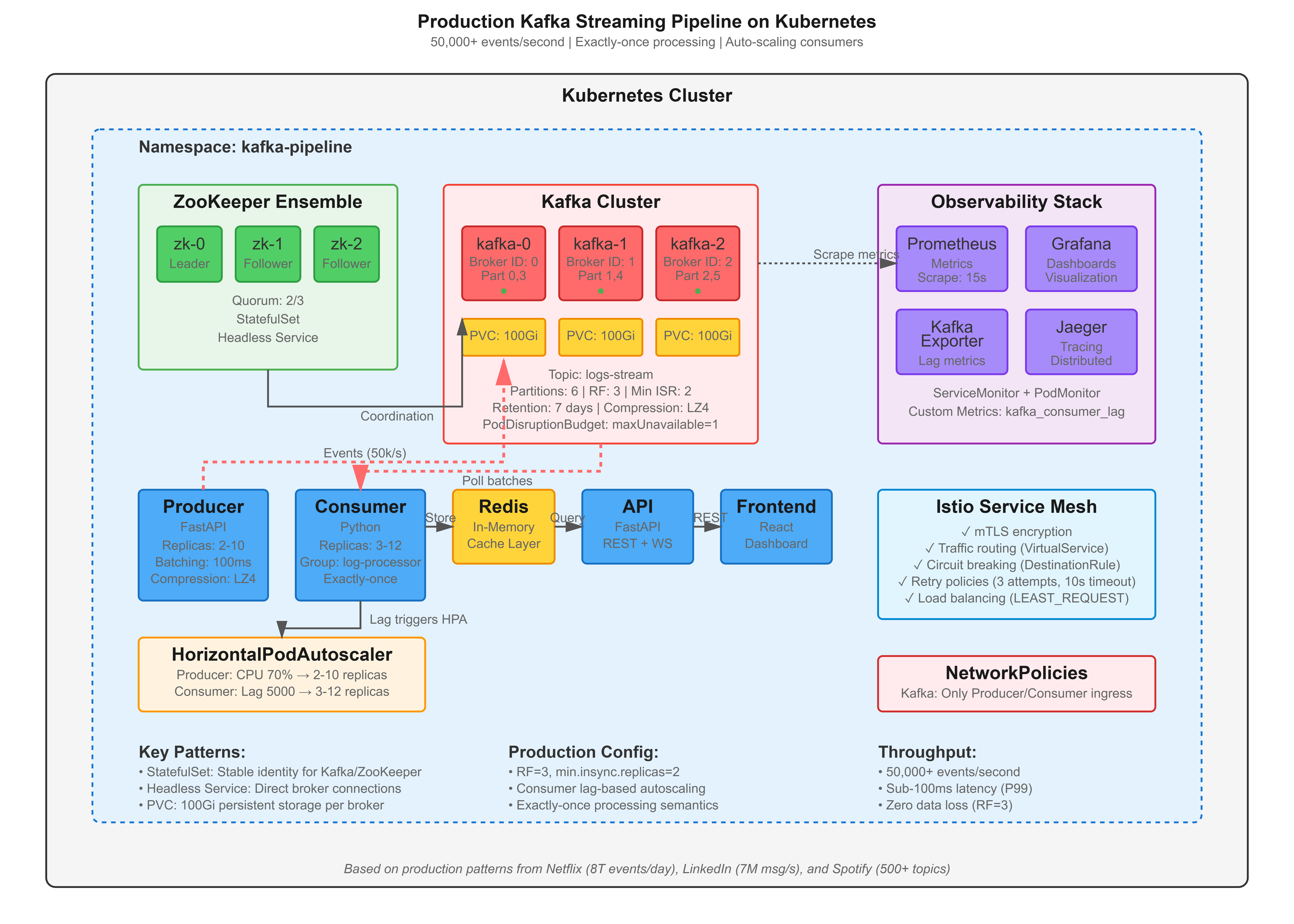
Production Kafka Cluster: 3-broker Kafka ensemble with ZooKeeper coordination, handling 50,000+ events/second
Real-Time Log Processing Pipeline: Event ingestion → stream processing → analytics aggregation with exactly-once semantics
Microservices Architecture: FastAPI producers/consumers + React real-time dashboard with WebSocket streaming
Complete Observability Stack: Kafka lag monitoring, consumer group tracking, and distributed tracing across the streaming pipeline
Why This Matters: The $2.8M Lesson from Uber’s Data Loss
In 2017, Uber experienced a catastrophic data loss that cost them $2.8 million in business impact—not from a security breach, but from improper Kafka replication configuration. When a datacenter failed, they discovered their critical trip data streams had replication factor of 1. No replicas meant no recovery.
Netflix processes 8 trillion events daily through Kafka. Spotify’s personalization engine relies on 500+ Kafka topics streaming user behavior. LinkedIn’s data infrastructure handles 7 million messages per second. These companies don’t use Kafka because it’s trendy—they use it because when you’re processing billions of events, traditional request-response patterns break down fundamentally.
The shift to event-driven architectures isn’t academic. At scale, synchronous communication creates cascading failures: one slow service blocks thousands of requests. Message queues decouple producers from consumers, enabling independent scaling. Kafka’s distributed log architecture provides the durability guarantees that make this practical for mission-critical data.